
前言
缓存可以说在计算机领域无处不见,底层硬件的Cpu高速缓存、磁盘缓存;处于网路边缘的Dns缓存、Web缓存、Http缓存、DNS;应用服务中的数据库缓存、分布式缓存、本地缓存等等。这些缓存都有哪些特点?为什么缓存被大量使用?有哪些优缺点?今天我们从横向分类归纳的方式来探讨一下这个问题。
一、为什么需要缓存?
在探讨为什么需要缓存之前,我们先来看看具体的几个例子,看看缓存在实际场景中给我们解决了哪些问题。
1、CPU高速缓存
首先我们来看第一种情况,众所周知,CPU可以直接访问的存储设备只有内存和内置的寄存器,如果数据没有处于这些存储设备中,那么需要先加载到内存中,CPU才能直接访问。
CPU访问内置寄存器通常在一个时钟周期便可完成。而对于内存来说就不行了,完成一次内存访问通常需要多个时钟周期才能完成,那么由于没有数据以便完成正在执行的指令,CPU通常需要暂停(stall),而且由于内存访问非常频繁(相对寄存器,内存的容量大得多),所有这种情况是无法容忍的。
解决上边CPU频繁暂停的办法是什么呢? 答案就是通过增加高速缓存(CPU访问速度比内存快很多)来调和CPU访问内存过慢的问题。具体原理可以参考coolshell的这篇文章
与此类似的场景还有磁盘缓存,同样是为了调和内存与磁盘之间速度的差异。
2、Web缓存
假设小明使用浏览器正在请求下载一个最新的Ubuntu ISO,链接为https://releases.ubuntu.com/20.04/ubuntu-20.04-desktop-amd64.iso,若资源的服务器地址在美国,那么由于链路过长,而下载的速度由整个链路的瓶颈决定的,所以整个下载速度将受到很多因素影响;于此同时,和你处于同一个局域网的另外一个人,也想下载同一个资源,那么他也不得不重新发起一个下载请求,忍受很慢的下载速度,且互联网的带宽是有上限的,大量重复的数据传输将大大增加链路的拥塞,从而导致整体下行速度更慢。
要解决这个问题的办法就是在用户和目标资源服务器之间增减WEB缓存,资源首次访问之后,将会缓存到Web缓存器(拥有自己的磁盘存储空间)中,在一段时间内相同区域内的用户也需要下载同样的资源的话,那么就可以直接在Web缓存中获取到资源,而不需要去访问远端的资源。从而减少因特网中的通信量,并且大大减少用户的请求时间。如下图:
二、缓存的分类
上边的对于CPU高速缓存和Web缓存的两种场景下缓存的使用,我将缓存分为两种类型。
1、调和速度差异型
见名知意,这类缓存主要的主要作用就是调和两种资源之间速度的差异,从而减少高速设备的等待时间,最终实现整体性能的提升。例如Cpu高速缓存、磁盘缓存、分布式缓存等等,都是此类目的。关于Cpu高速缓存的具体原理介绍,可以参考维基这篇文章
2、降低成本型
a、此类型可能更多的用于“网络边缘”设备,例如上边介绍的Web缓存。主要目的就是为了降低使用成本,当我们请求一个资源之后将缓存到距离我们更近的web缓存服务器中,当我们下次访问则可以直接命中局域网内已经缓存的资源,达到直接降低使用成本的目的。
b、还有例如我们使用Mysql数据库时,当我们执行一个Sql查询语句,数据库并不会立即去解析语法树、执行sql这些动作,而是先将计算此Sql的Hash值,然后通过这个Hash值去缓存中查询是否已经缓存,若命中直接返回之前已经缓存的结果给用户,这就能极大地降低查询成本。
c、我们在程序中通常会将计算/获取成本较高的数据缓存起来,以备下一次使用时直接在内存中访问,降低响应时间、提高服务的吞吐量。
使用缓存的场景非常非常多,但大体离不开这两种类型。有时候缓存兼具以上两种类型的特征,例如使用Redis做分布式缓存,既可以为调和数据库资源、访问速度有限的问题;同时也可将应用中需要频繁使用且计算成本高的数据缓存起来,实现降低使用成本的目的。
三、使用缓存需要注意的问题
通过上边的介绍,我们知道缓存给我们带来系统性能上的极大提升,但是使用缓存也需要注意下边的两个问题,否则“理想是美好的,现实是骨感的”。
1、如何解决数据一致性的问题?
首先在这里我们以”微观“的角度来分析多核CPU缓存一致性和来探讨。
多核CPU缓存一致性问题
我们首先来看一下为什么会产生缓存一致性的问题,假设cpu、cache、main memory的架构如下图所示:
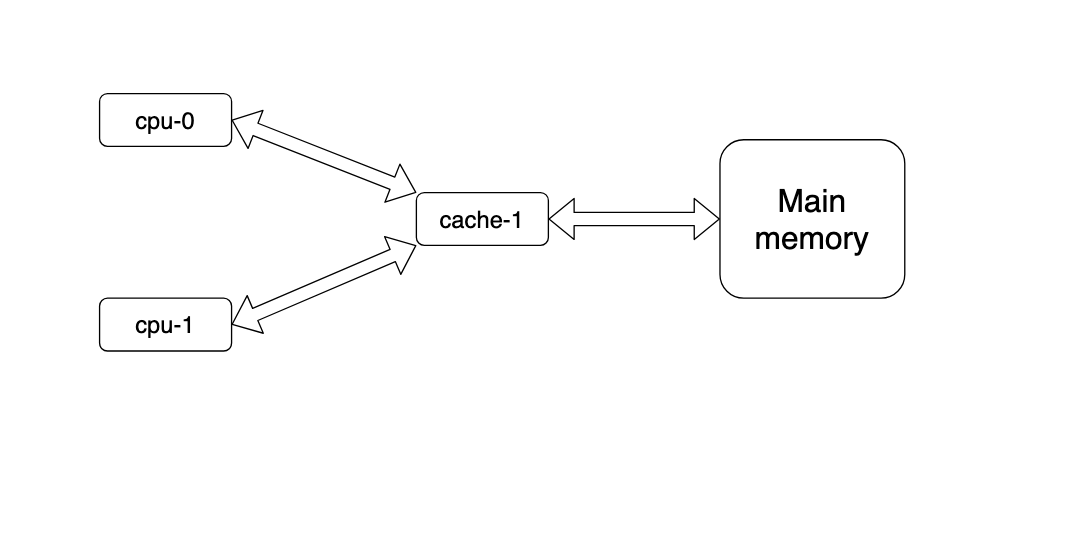
两个cpu共享同一个缓存,这样当缓存中的数据更新之后,cpu-0、cpu-1读取到的数据自然是相同的,此时不存在缓存一致性问题,但是由于此时缓存属于“临界区资源”,为了避免多核CPU同时读写而产生的临界区资源安全的问题,那么就需要加锁,那此时也就极大地降低了系统的运算速度,因为很多CPU都在排队等待缓存可用。所以现代CPU的架构都是每一个CPU都有属于自己的缓存,也就是说缓存一致性是多缓存引起的,而不是多CPU带来的。
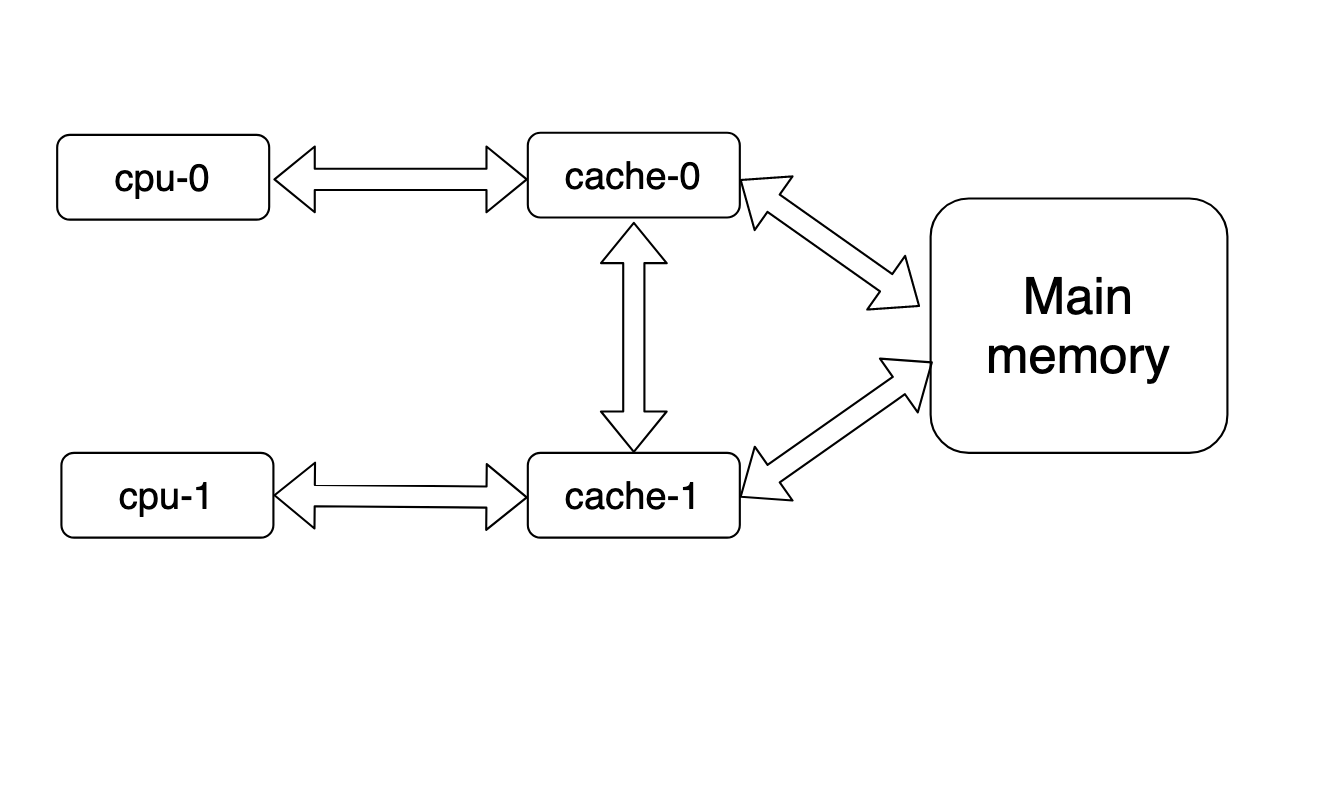
在上图中,假设一个消息m,更新到cache-0中,那么这个时候也需要立即将m更新到cache-1中,这就属于CPU缓存一致性问题了。
一般来说,在CPU硬件上,会有两种方法来解决这个问题。
- Directory 协议:这种方法的典型实现是要设计一个集中式控制器,它是主存储器控制器的一部分。其中有一个目录存储在主存储器中,其中包含有关各种本地缓存内容的全局状态信息。当单个CPU Cache发出读写请求时,这个集中式控制器会检查并发出必要的命令,以在主存和CPU Cache之间或在CPU Cache自身之间进行数据同步和传输。
- Snoopy 协议。这种协议更像是一种数据通知的总线型的技术。
CPU Cache通过这个协议可以识别其它Cache上的数据状态。如果有数据共享的话,可以通过广播机制将共享数据的状态通知给其它CPU Cache。这个协议要求每个CPU Cache都可以“窥探”数据事件的通知并做出相应的反应。
从上边两种协议的描述我们就可以看出,Directory协议是中心式的,会有性能瓶颈,而且会增加整体设计的复杂度。而Snoopy协议更像是微服务+消息通讯,所以,现在基本都是使用Snoopy的总线的设计。在分布式系统中我们一般用Paxos/Raft这样的分布式一致性的算法。而在CPU的微观世界里,则不必使用这样的算法,原因是因为CPU的多个核的硬件不必考虑网络会断会延迟的问题。所以,CPU的多核心缓存间的同步的核心就是要管理好数据的状态就好了。
对于数据状态管理的协议主要有:MESI协议、MOESI协议等等,具体可以参考维基百科的两篇文章:MESI协议、MOESI protocol
2、如何提高命中率?
在使用缓存的场景中,在如何提高命中率这一点,我们需要特别的重视,较高的缓存命中率可以大幅的提高我们系统的吞吐量,降低响应时间。这里我们从宏观角度来分析,这里以Redis为例。
我们先来看一下影响缓存命中率的几个关键点:
- 1、业务场景:我们在缓存数据之前要确认,当前的数据是否为**“读多写少” **?若相反,则没有必要使用缓存来增加系统的复杂度,直接查库即可。
- 2、数据粒度:通常来说,我们缓存数据的粒度相对小的时候,被命中的概率会比较高。举个例子,假设我们缓存班级里某一个学生的信息和缓存整个班级的信息相比,这个学生的信息在同样的时间范围内被修改的概率肯定是要小于班级里任意一个人被修改的概率,而数据数据一旦被修改,此时缓存失效,需要重新从DB中加载数据块,缓存也随之失效。
- 3、缓存容量和基础设施:Redis缓存之所以能够相比DB块,是因为缓存中的数据在内存中,但是我们知道内存容量相对磁盘是很有限的,所以缓存不可能一直在内存中驻留,那么就需要定义超时时间和缓存数据淘汰算法(目前大多数都采用LRU来作为淘汰算法)。为数据项定义合理的失效时间和淘汰算法对提高命中率也是非常重要的。
同时,缓存的技术选型也是至关重要的,比如采用应用内置的本地缓存就比较容易出现单机瓶颈,而采用分布式缓存则毕竟容易扩展。所以需要做好系统容量规划,并考虑是否可扩展。此外,不同的缓存框架或中间件,其效率和稳定性也是存在差异的。
要提高缓存的命中率,我们就需要在业务场景、粒度和策略、缓存容量和基础设施选型这几个方面去全面分析、妥协,达到一个综合效果最好的目的。
